表面增强拉曼光谱是一项指纹式的超灵敏检测技术,在生物医学、环境保护、食品安全等各个领域都展现出极高的应用价值。为了达到更高的检测灵敏度以及更加具有鲁棒性的检测能力,该技术可从增强基底的设计、拉曼信号分子的构建、合成路线的优化、仪器设备的改进以及数据处理和分析方法的建立等方面不断更新与发展。而人工智能(Artificial intelligence)得益于其在高层次表征学习和复杂特征识别中展现出的强大能力,可以模仿人类行为甚至超越人类智能。因此,面对如今数据规模的爆炸式增长以及各种内部因素的交织复杂,人工智能也逐步在表面增强拉曼光谱的全流程中被广泛应用(图1),加速了系统性的优化,加深了人们对于背后物理机制和光谱数据的理解,远超人脑计算与传统计算方法的能力。在本文中,作者回顾了近期人工智能在表面增强拉曼光谱中的进展,对未来挑战、解决方案与发展前景提出了新的见解。

图 1
首先,针对增强基底与报告分子,作者基于正向/反向设计(forward/inverse design)的人工智能及相应表示方式分别展开了讨论(图2)。正向设计路线,即根据已知的基底结构对其远场消光、近场增强、电荷迁移率等特性进行预测,或基于已知的分子结构对散射截面、最大吸收/发射波长、量子产率等性质进行推断;反向设计路线则根据目标特性,构建可能的基底/分子结构。其中对于基底和分子结构的表示方式很大程度上决定了算法所能够计算的范围,因此也需要根据具体的需求来选择合适的表示方式。常用的基底表示方式如具体结构参数(长、宽、直径等)以及二维/三维图片;对于分子结构的描述则相对更为复杂,需要考虑唯一性、分子内原子间作用等因素。目前,神经网络通常被用来同时实现正向/反向设计;而反向设计存在非唯一解,使用串联神经网络能够达到稳定的收敛效果。此外,神经网络的可解释性对于探索基底/分子背后的物化机制起着十分重要的作用,采用SHAP(SHapley Additive exPlanations)等方法可以帮助更好地挖掘决定特定性质的关键结构等信息。
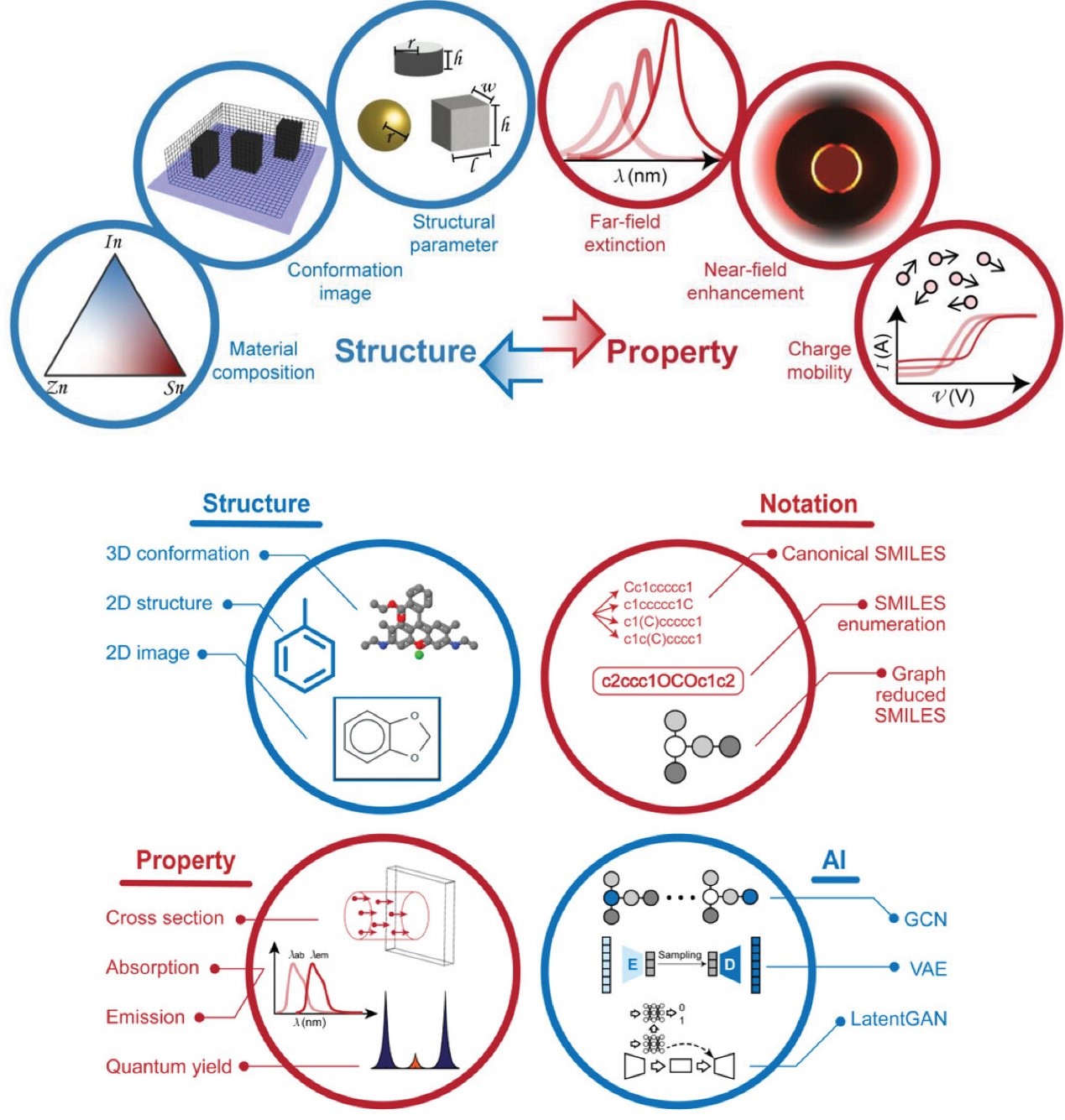
图2
表面增强拉曼光谱技术对于基底及分子结构十分灵敏,其微小的变化会引发巨大的谱峰特征与强度的差异,因此制备/合成路线的优化对于提升表面增强拉曼技术十分重要。通过文本挖掘(text mining)可以一次性获得大量的实验数据、实验现象和结果,从而探索实验条件与最终产物性质之间的关系。但由于文献中的描述通常会存在一定的偏颇,结合微流控实验平台与优化算法(包括遗传算法和贝叶斯优化),可以精确控制各种实验条件,融合在线自动化表征分析,及时获取分子的特性以实行进一步优化,从而获得能够达到目标特性的最优合成路线,目前已在金/银等纳米材料的合成路线开发中被广泛尝试(图3)。
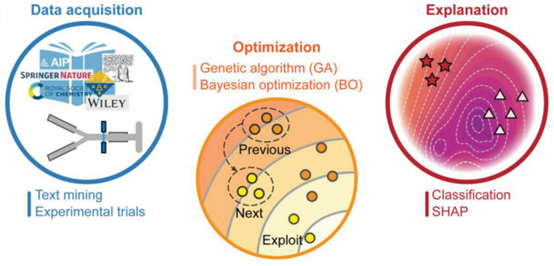
图3
在表面增强拉曼技术相关的硬件系统(如传输矩阵、入射光源形状、存储容量)、光谱预处理(去除宇宙射线、基线校准、降噪)等领域目前也有大量算法被开发(图4)。其中,采用循环一致生成对抗网络(cycle-consistent generative adversarial network)、降噪自编码器(denoising autoencoder)、卷积神经网络(CNN)与U-net的结合模型/级联模型可以实现多合一的处理能力,一步完成上述三项光谱预处理需求。
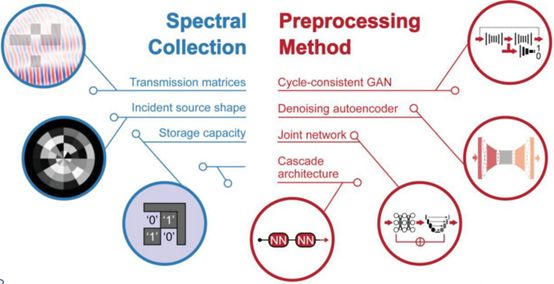
图 4
作者将表面增强拉曼光谱在各个领域的应用分为定性、定量、表型研究与成像四种类型(图5)。采用多元曲线分析(multivariate curve resolution)与人工神经网络等的方式可以将目标组分从混合光谱中区分开来,从而判断目标分子在体系中的有无,即定性。进一步地,解析某一组分在混合光谱中的贡献值,通过分类/回归计算不同组分之间的浓度比例和某一分子的浓度,结合一些矫正因子(如特征放大器characteristic amplifier)、迁移学习(transfer learning)有望减小混合体系的复杂变化对定量准确性带来的影响(包括多种分子在增强基底表面的竞争吸附、基质背景),从而扩大应用范围。在生物医学领域,表型检测可以实现高通量的分子测试,得益于表面增强拉曼光谱技术(尤其是非靶检测策略)的便捷性、高灵敏度以及高灵活度,其在各种疾病模型中被广泛研究,目前已有大量文献报道在癌症、退行性疾病等中实现了基于表型的高精准诊断与潜在标志物分子的挖掘。在成像应用中,采用人工智能相比传统基于单个特征峰的方法可以提高成像通量和灵敏度:对于标记成像,根据已有数据库进行多组分拆解,实现更多指标的成像以及微量标记的识别;对于非标记成像,可以自动提取主要成分,在成像的同时,为具体生物组成提供参考。
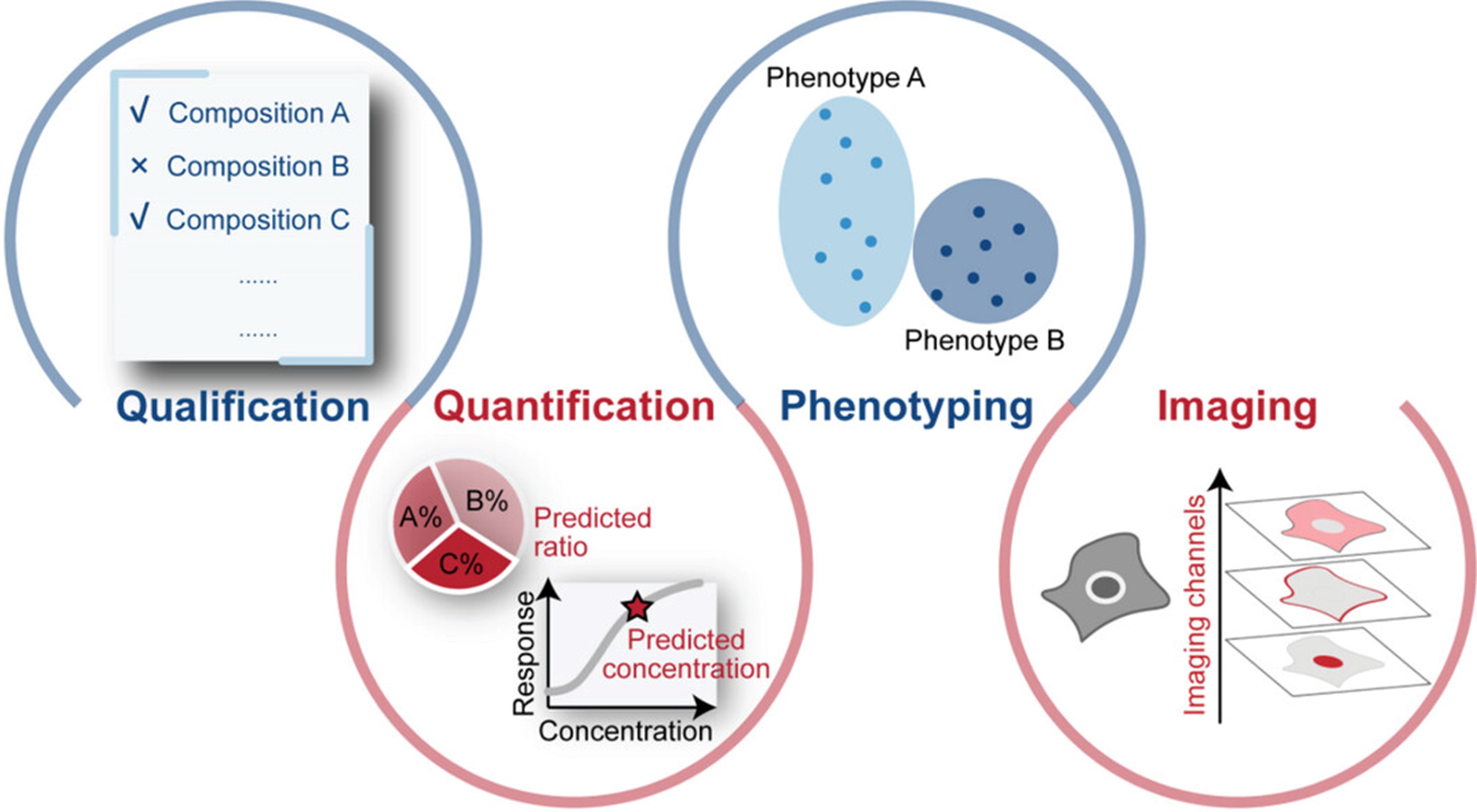
图 5
针对如今的人工智能在表面增强拉曼光谱中的使用,作者认为在样品准备、数据获取与使用等方面仍然存在未解决的问题以及尚可利用的发展机遇,包括:
(1) 重复性与质控:由于人为操作对于纳米尺度的不可控,重复性问题是表面增强拉曼光谱领域长期以来的挑战,作者呼吁实验过程与实验结果(尤其包含失败的结果)的全公开透明以及双盲实验的设计,有利于更好理解各种变量,从而提升重复性。此外,在实验中增加质控以及采用统一的实验与数据分析方法,将有利于进一步减小时序实验以及不同实验室之间的系统误差。
(2) 数据对齐:可以借鉴图像领域的数据对齐方式并迁移到拉曼光谱中,采用深度配准网络取代传统配准方法中的特征提取与特征匹配,以及在监督与非监督的模式下进行位姿优化。
(3) 数据质量:数据标签(ground truth或label)很大程度上决定了模型计算结果是否可信。通常情况下由于仪器误差、样本采样差异等因素会导致标签错误,而人工二次验证费时费力,在一些场景下几近不可能。因此可以通过在训练过程中引入不确定因子,或采用半监督的策略来减少影响。
(4) “大拉曼模型”:近年来,ChatGPT被广泛推广和使用,搭建基于开源大语言模型的大拉曼模型或开发拉曼光谱基础模型,集合众多拉曼数据训练大拉曼模型,有利于准确地理解拉曼数据背后的深层信息,提升拉曼技术对于生物、医学等基础研究的应用能力。
(5) 伦理问题:对于算法决策的解释是人工智能伦理中的一个重要方面,在算法效果与透明度之间的平衡、定量评估标准的建立、全面且标准的表面增强拉曼数据库可以进一步提升人工智能可解释性。此外,在数据共享与数据安全中尚存巨大挑战。
最后,作者倡议开发更多的用户界面可供公开使用,从而收集更多的用户需求与反馈意见,促进相关算法的更新迭代。此外,作者认为未来会进一步地发生从人工智能辅助(AI-assisted)到人工智能驱动(AI-driven)的模式转变,这种转变将革命性地改变表面增强拉曼光谱技术中包括识别、优化、发现、评估等方面的传统模式,最终提升表面增强拉曼光谱在各领域的应用能力。
关于本文
上海交通大学生物医学工程学院博士生毕心缘为本文的第一作者,上海交通大学生物医学工程学院叶坚教授和陈舟助理研究员为共同通讯作者。此工作还得到了国家自然科学基金委、上海市科学技术委员会,上海交通大学、上海市妇科肿瘤重点实验室的支持。
本文信息:Xinyuan Bi, Li Lin, Zhou Chen*, and Jian Ye*. Artificial Intelligence for Surface-Enhanced Raman Spectroscopy. Small Methods, 2023, 2301243.
原文链接:https://doi.org/10.1002/smtd.202301243
叶坚教授课题组主页:
供稿单位:叶坚教授课题组
作者:毕心缘
审核:叶坚









